안녕하세요,
[부스트코스] 캐글 실습으로 배우는 데이터 사이언스의 chapter 3 자전거 수요 예측의 마지막 강의인
다양한 모델 사용해 상위 5%이내 점수 얻기
실습내용 정리입니다!
강의 내용과 실제 코드 구현과 조금 차이가 있어 조금 수정하였습니다!
www.boostcourse.org/ds116/lecture/57571
캐글 실습으로 배우는 데이터 사이언스
부스트코스 무료 강의
www.boostcourse.org
부스트코스 강의 링크입니다!
처음에는 필요한 모듈을 import하고,
쥬피터 노트북 안에서 그래프 이용과 ggplot 사용, 폰트 문제 해결 위해 추가적 설정까지 했습니다.
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# 노트북 안에 그래프 그리기 위해
%matplotlib inline
# 그래프에서 격자로 숫자 범위가 눈에 잘 띄도록 ggplot 스타일 사용
plt.style.use('ggplot')
# 그래프에서 마이너스 폰트 깨지는 문제 해결 방법
mpl.rcParams['axes.unicode_minus'] = False
- 로컬과 웹에서 파일경로가 다르므로 이렇게 따로 선언하도록 했습니다.
- 캐글 사이트에 올릴때는 캐글 자체적으로 데이터를 다운받아서 업로드 할 수 있더라구요!
train_path = "train.csv"
test_path = "test.csv"
train = pd.read_csv(train_path, parse_dates=['datetime'])
# train.shape
print( train.shape,'\n')
train.head()
이렇게 shape와 head함수를 이용해서 train 데이터의 윗부분을 확인합니다.
피쳐와 전체적인 틀을 확인할 수 있습니다.
test= pd.read_csv(test_path, parse_dates=['datetime'])
print(test.shape)
test.head()

마찬가지로 test 데이터도 확인합니다!
그 후 DataFrame에 시간 데이터의 전부를 담지 않고,
연도, 월, 시간, 평일 등의 피쳐만 사용할 data features에 담도록 새로운 columns를 선언했습니다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['hour'] = train['datetime'].dt.hour
train['dayofweek'] = train['datetime'].dt.dayofweek
print(train.shape)
train.head()
test 데이터에서 연도, 월, 시간, 평일을 추가시켜 column수가 12 -> 16으로 증가했습니다!
test['year'] = test['datetime'].dt.year
test['month'] = test['datetime'].dt.month
test['hour'] = test['datetime'].dt.hour
test['dayofweek'] = test['datetime'].dt.dayofweek
print(test.shape)
test.head()

마찬가지로, test 데이터의 column수도 9-> 13으로 증가했습니다.
연속형 feature와 범주형 feature로 구분하기 위해 피쳐를 지정합니다.
categorical_feature_names = ["season",'holiday','workingday','weather',
'dayofweek','month','year','hour']
위에서 지정한 범주형 feature의 type을 for를 통해 하나씩 category타입으로 변경합니다.
for var in categorical_feature_names:
train[var] = train[var].astype("category")
test[var] = test[var].astype("category")
feature_names =["season",'weather','temp','atemp','humidity','year','hour',
'dayofweek','holiday','workingday']
feature_names
위에서 지정한 피쳐들로 train 데이터를 구성합니다.
X_train = train[feature_names]
print(X_train.shape)
X_train.head()
마찬가지로 test 데이터도 구성합니다!
X_test = test[feature_names]
print(X_test.shape)
X_test.head()
그리고 분류 하기 위한 label을 지정합니다.
label은 기존 train.csv 파일의 count 컬럼을 이용합니다.
이를 통해 y_train 데이터도 정의했습니다.
label_name = 'count'
y_train = train[label_name]
print(y_train.shape)
y_train.head()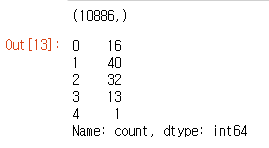
평가방식에 맞는 평가식 세우기
자전거 수요량 예측 컴피티션에서는 평가식으로 RMSLE식을 사용합니다.
평가 방법을 rmsle 사용하므로 평가 방법에 맞게 함수 통해 점수 계산을 해야합니다. !
따라서 rmsle 함수를 만들었습니다.
from sklearn.metrics import make_scorer
def rmsle(predicted_values, actual_values, convertExp=True):
if convertExp:
predicted_values = np.exp(predicted_values),
actual_values = np.exp(actual_values)
# numpy 배열 형태로 바꾸기
predicted_values = np.array(predicted_values)
actual_values = np.array(actual_values)
# 예측값과 실제값에 1을 더하고 로그를 씌우기
# 값이 0일 수도 있어서 로그를 취했을 때 마이너스 무한대가 될 수도 있기 때문에 1을 더해 주기
# 로그를 씌워주는 것은 정규분포로 만들어주기 위해서
log_predict = np.log(predicted_values + 1)
log_actual = np.log(actual_values + 1)
# 위에서 계산한 예측값에서 실제값을 빼주고 제곱하기.
difference = log_predict - log_actual
difference = np.square(difference)
# 평균을 낸다.
mean_difference = difference.mean()
# 다시 루트를 씌운다.
score = np.sqrt(mean_difference)
return score
이제 평가할 모델을 만들어 보도록 하겠습니다!
첫번째 모델은 선형회귀 모델입니다.
선형회귀 모델 Linear Regression Model
- - 선형회귀 또는 최소제곱법은 가장 간단하고 오래된 회귀용 선형 알고리즘 입니다.
- 선형회귀는 예측과 훈련 세트에 있는 타깃 y아이의 평균제곱오차(Mean Squre Error : MSE)를
최소화하는 파라미터 w와 b를 찾습니다. - 매개변수가 없는 것이 장점이지만, 모델의 복잡도를 제어할 수 없다는 단점이 있습니다.
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import warnings
pd.options.mode.chained_assignment = None
warnings.filterwarnings("ignore", category = DeprecationWarning)
# 선형회귀 모델 초기화
lModel = LinearRegression()
# 모델 학습
y_train_log = np.log1p(y_train)
lModel.fit(X_train, y_train_log)
# 예측하고 정확도 평가
predicts = lModel.predict(X_train)
print('RMSLE Value For Linear Regression: ',
rmsle(np.exp(y_train_log), np.exp(predicts),False))
[out]
RMSLE Value For Linear Regression: 0.9803697923313522이 모델을 통해 예측값의 정확도가
약 98%값이 나오는 것을 확인할 수 있습니다.
두 번째 모델로는
릿지(Regularization Model - Ridge)
- - 회귀를 위한 선형모델
- 가중치(w)의 모든 원소가 0에 가깝게 만들어 모든 피처가 주는 영향을 최소화(기울기를 작게 만듦)
- Regularization(규제)는 오버비팅(과적합)이 되지 않도록 모델을 강제로 제한한다는 의미입니다.
- max_iter(반복 실행하는 최대 횟수)는 3000을 주었습니다.

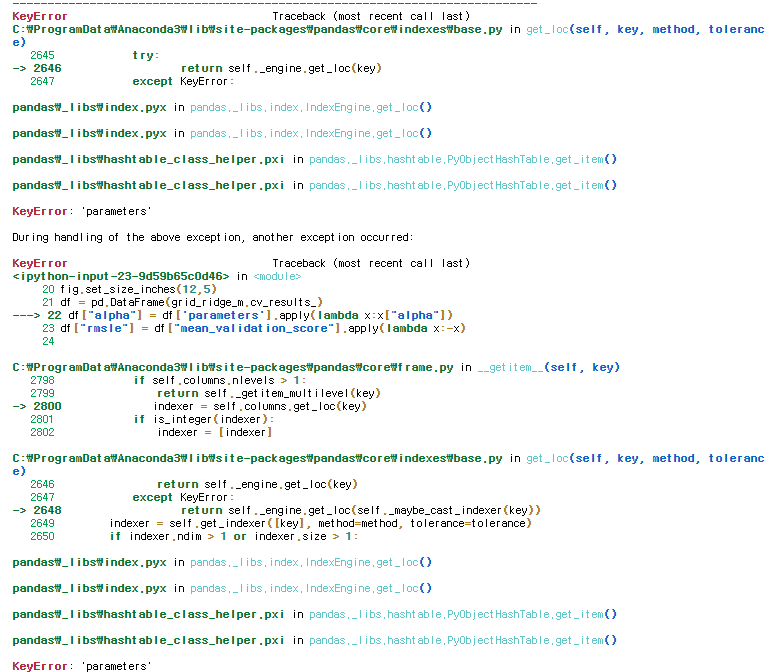

이렇게 에러가 나게 됩니다.
이때, 저는 두 가지 문제를 발견했습니다.
첫 번째 문제로는 grid_grid_ridge_m을 지정할때 GGridSearchCV함수의 파라미터를 잘못입력했었습니다.
두번째 문제로는 Dataframe의 컬럼 명과 코드에서 컬럼명이 달라 위와같은 파라미터 에러가 나오게 되었음을 인지하였습니다.
따라서 이 문제를 해결하기 위해 df.head()를 통해 컬럼명을 다시 확인했습니다.
df.head()

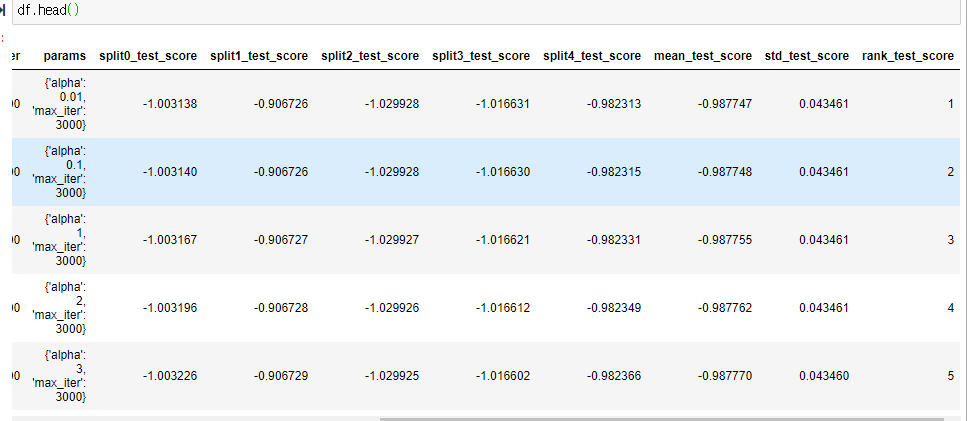
여기서 위와 같이 parameters가 아닌 params로 되어있었고,
mean_validation_score가 아닌 mean_test_score를 사용했습니다.
ridge_m_ = Ridge()
ridge_params_ = {'max_iter':[3000], 'alpha':[0.01, 0.1, 1,2,3,4,10,30,100,200,300,400,800,900,1000]}
rmsle_scorer = metrics.make_scorer(rmsle, greater_is_better = False)
grid_ridge_m = GridSearchCV( ridge_m_,
ridge_params_ ,
scoring = rmsle_scorer,
cv = 5 )
y_train_log = np.log1p(y_train)
grid_ridge_m.fit( X_train, y_train_log)
preds = grid_ridge_m.predict(X_train)
print(grid_ridge_m.best_params_)
print('RMSLE Value For Ridge Regression: ',
rmsle(np.exp(y_train_log), np.exp(preds),False))
fig,ax = plt.subplots()
fig.set_size_inches(12,5)
df = pd.DataFrame(grid_ridge_m.cv_results_)
df["alpha"] = df['params'].apply(lambda x:x["alpha"])
df["rmsle"] = df["mean_test_score"].apply(lambda x:-x)
plt.xticks(rotation=30, ha='right')
sns.pointplot(data=df,x="alpha",y="rmsle",ax=ax)
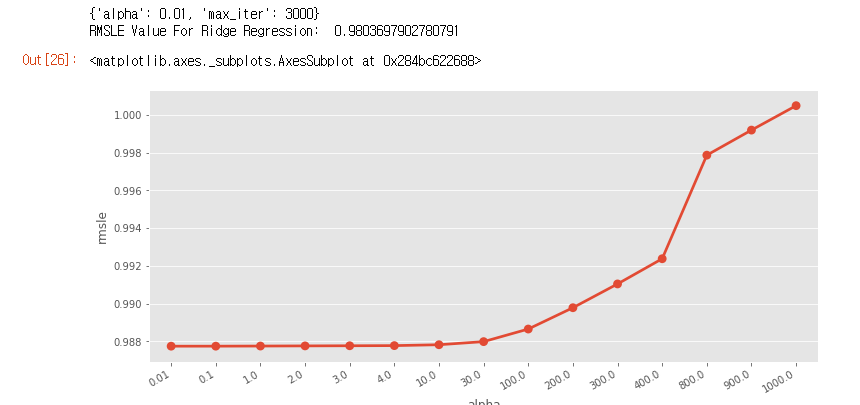
그러면 이렇게 alpha - msle 그래프를 시각화해서 확인할 수 있습니다!
최적의 alpha값은 0.01 일때,
릿지 회귀의 RMSLE값은 0.98임을 확인할 수 있습니다.
라쏘 Regularization Model - Lasso
- 선형회귀의 Regularization(규제)를 적용하는 대안
- 계수를 0에 가깝게 만들려고 하며 이를 L1규제라고 한다.
- 어떤 계수는 0이 되기도 하는데 이는 완전히 제외하는 피처가 생긴다는 의미다.
- 피처 선택이 자동으로 이루어진다고도 볼 수 있다.
- alpha 값의 기본 값은 1.0이며, 과소 적합을 줄이기 위해서는 이 값을 줄여야 한다.
- 그리드 서치로 아래 라쏘모델을 실행했을 때 베스트 알파값은 0.0025이다.
- max_iter(반복 실행하는 최대 횟수)는 3000이다.
lasso_m_ = Lasso()
alpha = 1/np.array([0.1, 1, 2, 3, 4, 10, 30,100,200,300,400,800,900,1000])
lasso_params_ = { 'max_iter':[3000],'alpha':alpha}
grid_lasso_m = GridSearchCV( lasso_m_,lasso_params_,scoring = rmsle_scorer,cv=5)
y_train_log = np.log1p(y_train)
grid_lasso_m.fit( X_train , y_train_log )
preds = grid_lasso_m.predict(X_train)
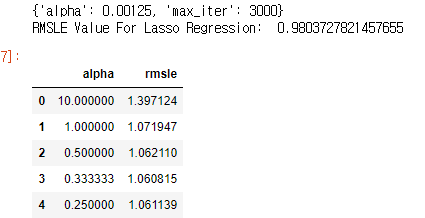
print (grid_lasso_m.best_params_)
print ("RMSLE Value For Lasso Regression: ",rmsle(np.exp(y_train_log),np.exp(preds),False))
df = pd.DataFrame(grid_lasso_m.cv_results_)
df["alpha"] = df["params"].apply(lambda x:x["alpha"])
df["rmsle"] = df["mean_test_score"].apply(lambda x:-x)
df[["alpha", "rmsle"]].head()여기서도 위와 마찬가지로 df["params"] 와 df["mean_test_score"] 수정해주세요!
fig,ax= plt.subplots()
fig.set_size_inches(6,3)
plt.xticks(rotation=50, ha='right')
sns.pointplot(data=df,x="alpha",y="rmsle",ax=ax)

그러면 이렇게 라쏘 모형도 시각화 한 그래프를 얻을 수 있습니다.
앙상블모델 - 랜덤포레스트
Ensemble Models - Random Forest
from sklearn.ensemble import RandomForestRegressor
rfModel = RandomForestRegressor(n_estimators=100)
y_train_log = np.log1p(y_train)
rfModel.fit(X_train, y_train_log)
preds = rfModel.predict(X_train)
score = rmsle(np.exp(y_train_log),np.exp(preds),False)
print ("RMSLE Value For Random Forest: ",score)
[out]
RMSLE Value For Random Forest: 0.10689565604094677
앙상블모델 - 그라디언트 부스트
Ensemble Model - Gradient Boost
- 여러개의 결정트리를 묶어 강력한 모델을 만드는 또 다른 앙상블 기법
- 회귀와 분류에 모두 사용할 수 있음
- 랜덤포레스트와 달리 이진 트리의 오차를 보완하는 방식으로 순차적으로 트리를 만든다.
- 무작위성이 없고 강력한 사전 가지치기가 사용 됨
- 1~5개의 깊지 않은 트리를 사용하기 때문에 메모리를 적게 사용하고 예측이 빠름
- learning_rate : 오차를 얼마나 강하게 보정할 것인지를 제어
- n_estimator의 값을 키우면 앙상블에 트리가 더 많이 추가 되어 모델의 복잡도가 커지고 훈련세트에서의 실수를 바로잡을 기회가 많아지지만 너무 크면 모델이 복잡해지고 오버피팅(과대적합)이 될 수있다.
- max_depth(max_leaf_nodes) 복잡도를 너무 높이지 말고 트리의 깊이가 5보다 깊어지지 않게 한다.
from sklearn.ensemble import GradientBoostingRegressor
gbm = GradientBoostingRegressor(n_estimators=4000, alpha=0.01);
y_train_log = np.log1p(y_train)
gbm.fit(X_train, y_train_log)
preds = gbm.predict(X_train)
score = rmsle(np.exp(y_train_log),np.exp(preds),False)
print ("RMSLE Value For Gradient Boost: ", score)
[out]
RMSLE Value For Gradient Boost: 0.2135740372724937predsTest = gbm.predict(X_test)
fig,(ax1,ax2)= plt.subplots(ncols=2)
fig.set_size_inches(12,5)
sns.distplot(y_train,ax=ax1,bins=50)
sns.distplot(np.exp(predsTest),ax=ax2,bins=50)
Submit
submission = pd.read_csv("./sampleSubmission.csv")
submission
submission["count"] = np.exp(predsTest)
print(submission.shape)
submission.head()
결과 파일을 저장하기 위해 경로를 지정하고 결과 값의 점수를 파일 명으로 지정해주도록 설정합니다.
save_path = '..'
submission.to_csv( save_path+'/Score_{0:.5f}_submission.csv'.format(score),
index=False)
그러면 이렇게


그러면 이렇게 Score csv파일이 만들어지게 됩니다!
이제 이 파일로 kaggle에 submit 해보겠습니다!
www.kaggle.com/c/bike-sharing-demand/overview

캐글에서 Bike Sharing Demand Compete에 들어가서
Late Submission으로 들어갑니다.

마지막에 저장한 score csv파일을 step1에 올립니다.
그리고 step 2에 간단한 소개 글을 쓰고
이제 제출을 해보겠습니다.

제출이 완료되면, 이렇게 업로딩이 되면서 Score가 나오게 됩니다.
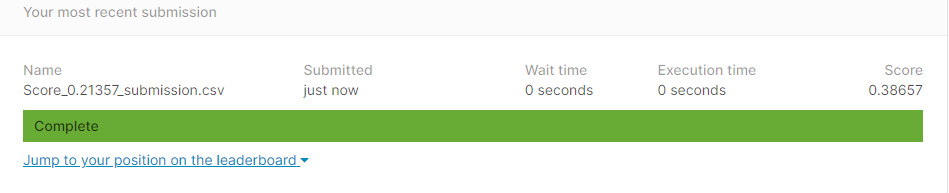
이 모델링을 통해 얻은 점수는 0.38657입니다.
왼쪽 아래에 leaderboard를 통해 등수를 확인해보면, 대략 143 등과 144등 사이입니다!
전체

전체 참가팀이 3,242팀이므로
144 / 3242 = 0.044
당시 기준으로 상위 약 4.4%의 성적을 거둘 수 있었습니다.
이렇게 하나씩 연습해가며
이후에는 제가 직접 참가해보고 후기를 남기도록 하겠습니다!
감사합니다 :)
이렇게 캐글 경진대회에 직접 참가하고 submission까지 진행할 수 있는 좋은 수업을 제공해주신
부스트코스와 박조은 강사님께 감사 인사를 드리고 싶습니다 ! 👏👏🙏
그리고 이 강의 코드 전체를 오픈해놓으신 박조은 강사님의 코랩 주소입니다.
colab.research.google.com/drive/12kQ7yeO9K-qenuD8L5j2dLxA8IUBz302
Google Colaboratory
colab.research.google.com
'Make the Learning Curve > 부스트코스' 카테고리의 다른 글
| [부스트코스] 프로젝트로 배우는 데이터사이언스 / 사이킷-런(scikit-learn) - Machine Learning in Python (0) | 2021.01.18 |
|---|---|
| [부스트코스] Kaggle 실습으로 배우는 데이터 사이언스 수료 (0) | 2020.12.24 |
| [부스트코스] 캐글 실습으로 배우는 데이터 사이언스 (0) | 2020.12.24 |
| [Kaggle] 캐글 첫 Commit (0) | 2020.12.23 |
| [부스트코스] 캐글 실습으로 배우는 데이터 사이언스 - 사이킷런 (0) | 2020.11.23 |




댓글