-
안녕하세요, 에이도입니다.
이번에 소개해드리고 싶은 교육은 DACON에서 진행하는 Pandas 튜토리얼입니다.
DACON(우리나라의 캐글 같은 AI 경진대회)에서 무슨 대회 진행하고있는지, 어떤 토픽을 기준으로 평가하는지 알아보기 위해서 사이트에 들어갔다가
메뉴 텝에 교육이라는 프로그램이 있기에 한번 들어가 보았습니다.
교육 - DACON
1만 AI팀이 협업하는 인공지능 플랫폼.
dacon.io
여기서 모두의 캠프 - MNIST , 의류 클래스 예측 등 여러가지 유명한 예측 대회를 직접 참가해 볼 수 도 있습니다.
저는 지금 시간이 조금 있을때 pandas를 다시 remind하기 위해서 Pandas 튜토리얼 을 시작했습니다.
총 7개의 chapter로 구성되어있고, 한 챕터당 2,30분 안에는 모두 끝나기 때문에 가볍게 remind 하기 좋은 프로그램입니다!
(홍보 절대 아닙니당..! )
저는 오늘 오전부터 시작해서 CH04까지 진행했습니다.
각 챕터에서 배운 내용을 마지막에 제출하는 기능도 있어 제출을 하고나면, 소소한 뿌듯함도 느껴집니다.
제가 Ch1 부터 Ch4까지 진행한 내용을 소개해 드리겠습니다.
Ch1. CSV 파일과 데이터프레임
목표 : 데이터를 다룰 때 가장 많이 접하는 CSV파일에 대해 배우고, 엑셀 표와 유사한 데이터프레임 구조에 대해서 학습

# 절대 경로 C:/Users/82103/2_데이콘/data/대한민국_주요_도시_인구수.csv
path_1 = 'C:/Users/82103/2_데이콘/data/대한민국_주요_도시_인구수.csv '
# 상대 경로 data/ 대한민국_주요_도시_인구수.csv
path_2 = 'data/대한민국_주요_도시_인구수.csv '
pd.read_csv(path_2)
data = pd.read_csv(path_2)
data
[out]
도시 인구수
0 서울 9741381
1 부산 3416918
2 인천 2925967
3 대구 2453041
4 대전 1525849
5 광주 1496172
6 수원 1193894
7 울산 1147037
8 고양 1068641
9 용인 1061440
shape, head, tail 함수 사용
shae 함수
- csv 데이터의 사이즈를 로우, 컬럼 튜플 형태로 표현
- data = (10x2) 사이즈 입니다.
data.shape
[out]
(10,2)
head(), tail()
- data.head(n) : 데이터의 상단 n개의 로우(행) 데이터 출력
- data.tail(n) : 데이터의 하단 n개의 로우(행) 데이터 출력
- Default = 5입니다.
print(data.head(3) ,'\n ... '*3+'\n' ,data.tail(3))
[out]
도시 인구수
0 서울 9741381
1 부산 3416918
2 인천 2925967
...
...
...
도시 인구수
7 울산 1147037
8 고양 1068641
9 용인 1061440
정보확인 (info)
- 컬럼의 개수
- 로우의 개수
- 각 컬럼의 이름
- 자료형 등의 정보를 알 수 있습니다.
data.info()
[out]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 도시 10 non-null object
1 인구수 10 non-null int64
dtypes: int64(1), object(1)
memory usage: 288.0+ bytes
특정 컬럼을 선택하는 2가지 방법
- DataFrame['특정 컬럼']
- DataFrame.컬럼 (특정컬럼에 띄어쓰기가 있을 경우 사용 불가)
print(data['도시'], '\n',data.도시)
print(data['인구수'],'\n', data.인구수 )
[out]
0 서울
1 부산
2 인천
3 대구
4 대전
5 광주
6 수원
7 울산
8 고양
9 용인
Name: 도시, dtype: object
0 서울
1 부산
2 인천
3 대구
4 대전
5 광주
6 수원
7 울산
8 고양
9 용인
Name: 도시, dtype: object
0 9741381
1 3416918
2 2925967
3 2453041
4 1525849
5 1496172
6 1193894
7 1147037
8 1068641
9 1061440
Name: 인구수, dtype: int64
0 9741381
1 3416918
2 2925967
3 2453041
4 1525849
5 1496172
6 1193894
7 1147037
8 1068641
9 1061440
Name: 인구수, dtype: int64
Ch2. DataFrame 생성과 저장
Pandas를 활용해 데이터프레임을 생성해보고 저장
DataFrame 생성
- 비어있는 데이터 프레임 생성
=> pd.DataFrame()
import pandas as pd
# 컬럼 : 도시, 인구수
# index(row) : 0 -9까지 생성
data = pd.DataFrame(columns = ['도시', '인구수'], index = range(10))
data
# 이 외에도 데이터프레임의 행,열 선언에는 여러가지 방법이 있습니다.
[출력]

- 리스트를 이용한 DataFrame
city = ['서울', '부산', '인천', '대구', '대전',
'광주', '수원', '울산', '고양', '용인']
population = [9741381, 3416918, 2925967, 2453041, 1525849,
1496172, 1193894, 1147037, 1068641, 1061440]
# 리스트를 dataframe에 채워넣기
data['도시'] = city # '도시'column에 city 리스트 값들 할당
data['인구수'] = population # '인구수'column에 population 리스트 값들 할당
data[출력]

- 딕셔너리를 이용한 DataFrame
city = ['서울', '부산', '인천', '대구', '대전',
'광주', '수원', '울산', '고양', '용인']
population = [9741381, 3416918, 2925967, 2453041, 1525849,
1496172, 1193894, 1147037, 1068641, 1061440]
# 딕셔너리를 dataframe에 채워넣기
# {'컬럼명' : 컬럼 값s}
data_dict = {'도시':city,
'인구수':population}
data = pd.DataFrame(data_dict)
data[출력]

DataFrame을 CSV로 저장
- pd.DataFrame.to_csv() 함수를 이용하여 DataFrame을 csv로 저장합니다.
- pd.DataFrame.to_csv('저장경로/파일명.csv')
저장경로 및 파일명 외에도 index, header 변수가 있습니다.
index와 header의 기본값(Default)은 True입니다.
index가 True이면 DataFrame의 인덱스가 하나의 컬럼으로 추가됩니다.
header가 False면 컬럼명을 제외하고 저장합니다.
data.to_csv('data/data2_pandas.csv', index = True , header = True)
pd.read_csv('data/data2_pandas.csv')

data.to_csv('data/data2_pandas.csv', index = False , header =False)
pd.read_csv('data/data2_pandas.csv')
data.to_csv('data/data2_pandas.csv', index = True , header = False)
pd.read_csv('data/data2_pandas.csv')
data.to_csv('data/data2_pandas.csv', index = False , header = True)
pd.read_csv('data/data2_pandas.csv')
Ch3 컬럼과 로우 추가
목표 : 데이터 프레임에 컬럼과 로우를 추가
import pandas as pd
# 이전에 생성했던 파일 불러오기
data = pd.read_csv('data/data2_pandas.csv')
data
인구수 컬럼 추가
- 남자 , 여자 인구수 컬럼 추가
- men = [4757642, 1680933, 1472081, 1218326, 765718, 745122, 601097, 589233, 523803, 526824]
- women = [4984229, 1735985, 1453886, 1234715, 760131, 751050, 592797, 557804, 544838, 534617]
men = [4757642, 1680933, 1472081, 1218326, 765718, 745122, 601097, 589233, 523803, 526824]
women = [4984229, 1735985, 1453886, 1234715, 760131, 751050, 592797, 557804, 544838, 534617]
data['남자'] = men
data['여자'] = women
data
인구수 총합 로우 추가
- 각 컬럼의 총합은 pd.DataFrame.sum() 함수를 이용하여 쉽게 계산 할 수 있습니다.
data.sum()
[out]
도시 서울부산인천대구대전광주수원울산고양용인
인구수 26030340
남자 12880779
여자 13150052
dtype: object(데이터 프레임 행렬 더하기도 가능한 걸 배웠습니다 ! )
row는 pd.DataFrame.loc[]을 이용하여 추가합니다.
[]안에 추가 할 row의 index를 입력하면, 그 index에 값을 추가합니다.
data.loc[10] = data.sum()
data[출력]
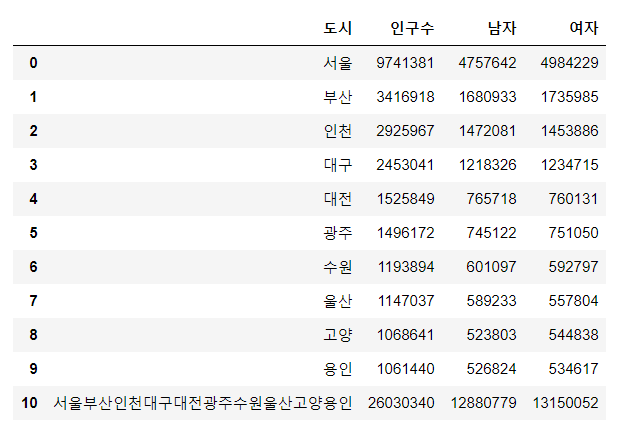
마지막 row가 너무 지저분하죠?
마지막 index의 값을 바꿔보겠습니다.
- 특정값 변경
pd.DataFrame.sum()이 도시의 이름을 모두 이어붙여서 원하지 않는 값이 저장되었습니다.
특정 위치의 값 역시 loc을 이용하여 변경이 가능합니다.
pd.DataFrame.loc[인덱스, 컬럼]으로 특정 위치를 지정하고 원하는 값을 저장합니다.
data.loc[10, '도시'] ='총합'
data[출력]

# 결과 저장
data.to_csv('data/data3_pandas.csv', index = False)
pd.read_csv('data/data3_pandas.csv')
Ch4 다중 컬럼, 로우 선택
목표 : 여러 개의 컬럼(column)과 로우(row)를 선택하는 방법
(위에서 저장한 data를 사용했습니다.)
- 로우를 부분적으로 선택
pd.DataFrame[시작_로우_번호 : 끝_로우_번호]
# print( data[2:4] ,'\n', data[3:8],'\n', data[5:])
data[5:9]
다중 column과 다중 row를 선택하는 방법 2가지
- pd.DataFrame.loc : row와 column의 index로 데이터에 접근하는 방법
- pd.DataFrame.iloc : row와 column의 위치로 데이터에 접근하는 방법
1) loc
- pd.DataFrame.loc[[로우_인덱스1, 로우_인덱스2,...], ['컬럼명 1', '컬럼_명2',...]]
- pd.DataFrame.loc[시작_로우_인덱스:끝_로우_인덱스, 시작_컬럼_인덱스:끝_컬럼_인덱스]
# pd.DataFrame.loc[[로우_인덱스1, 로우_인덱스2,...], ['컬럼명 1', '컬럼_명2',...]]
data.loc[[1,2,5,7],['인구수','남자']]
# pd.DataFrame.loc[시작_로우_인덱스:끝_로우_인덱스, 시작_컬럼_인덱스:끝_컬럼_인덱스]
data.loc[2:8, '인구수':'여자']
2. iloc
- pd.DataFrame.iloc[[로우_위치1, 로우_위치2, 로우_위치3...], [컬럼_위치1, 컬럼_위치2, 컬럼_위치3...]]
- pd.DataFrame.iloc[시작_로우_위치:끝_로우_위치, 시작_컬럼_위치:끝_컬럼_위치]
# pd.DataFrame.iloc[[로우_위치1, 로우_위치2, 로우_위치3...], [컬럼_위치1, 컬럼_위치2, 컬럼_위치3...]]
data.iloc[[1,2,5,7], [1, 2]]
# pd.DataFrame.iloc[시작_로우_위치:끝_로우_위치, 시작_컬럼_위치:끝_컬럼_위치]
data.iloc[2:8, 1:4]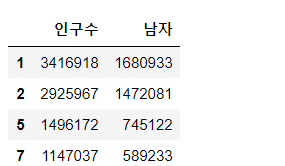
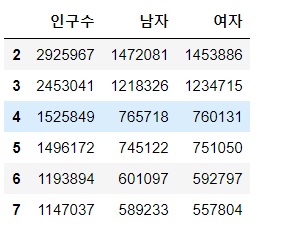
Ch4 과제 정답입니다 !
sub_data = data.iloc[3:6, 1:4]
sub_data.to_csv('data/data4_pandas.csv', index= False)
pd.read_csv('data/data4_pandas.csv')

'Make the Learning Curve > Python' 카테고리의 다른 글
| [Python] pyautogui를 이용한 마우스 자동화(feat. ppt 자동 인쇄) (0) | 2021.03.03 |
|---|---|
| [Python] Pandas 튜토리얼 (Feat.DACON _ Ch 05 - 07) (0) | 2021.01.08 |
| [Python] heapq (힙큐)사용 (0) | 2021.01.04 |
| [Python] Sort() , sorted() 정렬 함수 (0) | 2020.12.20 |
| [알고리즘] 선택 정렬 (0) | 2020.12.18 |




댓글