공유 자전거 수요량 예측(Bike Sharing Demand)
1. data set을 다운로드 받습니다!
www.kaggle.com/c/bike-sharing-demand/data
Bike Sharing Demand
Forecast use of a city bikeshare system
www.kaggle.com
2. 저는 Jupyter Notebook을 사용했습니다.
3. 문제 파악 : Regression (회귀)분석 모형입니다.
머신러닝의 지도 / 비지도 학습 중 지도 학습입니다.
왜냐하면, 특정상황에 따른 count가 존재하기 때문에 회귀(Regression)분석 문제입니다!
(참고)쥬피터노트북에서 밑에 Shell을 추가할때, ESC + B 버튼을 누르면 밑에 Shell이 추가됩니다!
또한 위에 Shell을 추가하고 싶을때는 , ESC+A를 누르면 위에 Shell이 추가됩니다.
참고해주세요!
4. 각 종 모듈 import하기.
여기부터 코드는 부스트코스 - 캐르 실습으로 배우는 데이터사이언스 강의의 코드를
직접 보며 코딩했습니다!

캐글에서 받은 훈련데이터(train.csv)를
pandas를 이용해서 불러오기 이때, 순서는 날짜(datetime)순서로 불러왔습니다.
head를 통해 위의 5개 요약해서 보기.
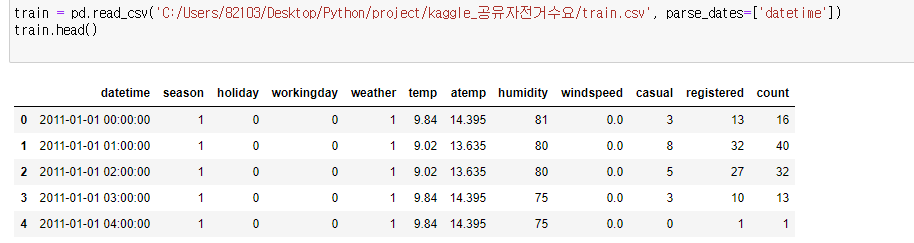
이때 head( n ) n자리에 정수를 입력하면,
아래와 같이 n개의 행열을 위에서부터 불러와 확인할 수 있습니다!

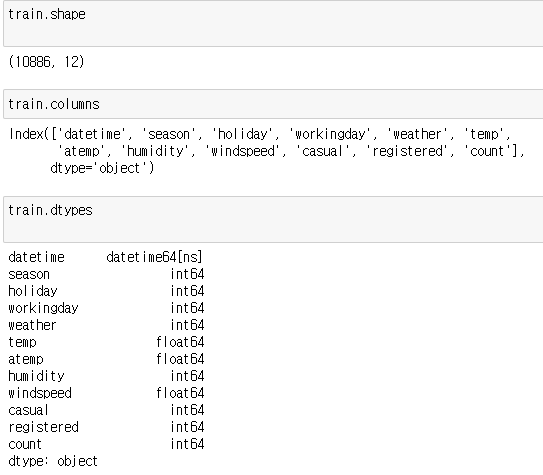
shape를 이용해 Matrix의 각 행과 열의 갯수를 파악할 수 있습니다!
그리고 columns를 통해 행을 확인할 수있고,
dtypes를 통해 위에서 확인한 행에 따라 다양한 datatype을 확인할 수 있습니다.
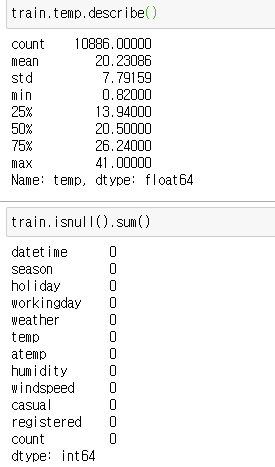
describe를 통해 boxplot의 기본 element를 확인할 수 있습니다.
isnull을 통해 nan의 개수를 카운트했는데 0으로 확인할 수 있었습니다!
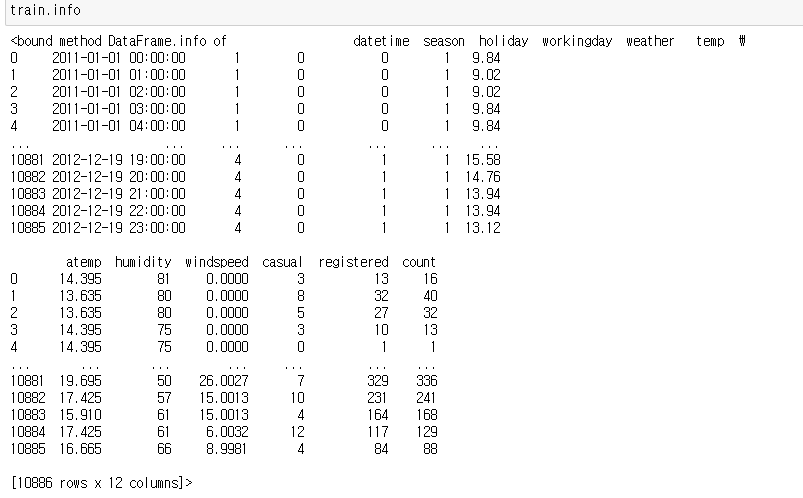
info를 사용하면 위에서 본 정보들을 더 자세하게 확인할 수 있습니다!
train의 datetime행을 연-월-일-시-분-초 를 추가해서 정렬했습니다.
dataframe을 저장한 parameter에 []을 붙여서 str형태의 column명을 쓰게되면,
그 column에 대한 명령(수정, 추가 등)을 내릴 수 있습니다.
이렇게해서 12개였던 행이 18개의 행이 되었습니다.

이제 위의 train데이터를 시각화 하기 위해서 table을 만들어줍니다!
그리고 이제 그래프를 그리기 위해 각 x축을 연도, 월, 일 , 시간, 분, 초로 그리고 y를 각 각의 count로 6개의 그래프를 그립니다.
그리고 ylabel과 xlabel을 하기위해 실행시켰는데,
figure,((ax1, ax2, ax3), (ax4, ax5 ,ax6) ) = plt.subplots(nrows = 2 , ncols = 3)
figure.set_size_inches(18,8)
sns.barplot(data=train, x='year', y='count', ax=ax1)
sns.barplot(data=train, x='month', y='count', ax=ax2)
sns.barplot(data=train, x='day', y='count', ax=ax3)
sns.barplot(data=train, x='hour', y='count', ax=ax4)
sns.barplot(data=train, x='minute', y='count', ax=ax5)
sns.barplot(data=train, x='second', y='count', ax=ax6)
ax1.set(ylabel= 'count', title='연도별 대여량')
ax2.set(xlabel= 'month', title='월별 대여량')
ax3.set(xlabel= 'day', title='일별 대여량')
ax4.set(xlabel= 'hour', title='시간별 대여량')
ax5.set(xlabel= 'minute', title='분별 대여량')
ax6.set(xlabel= 'second', title='초별 대여량')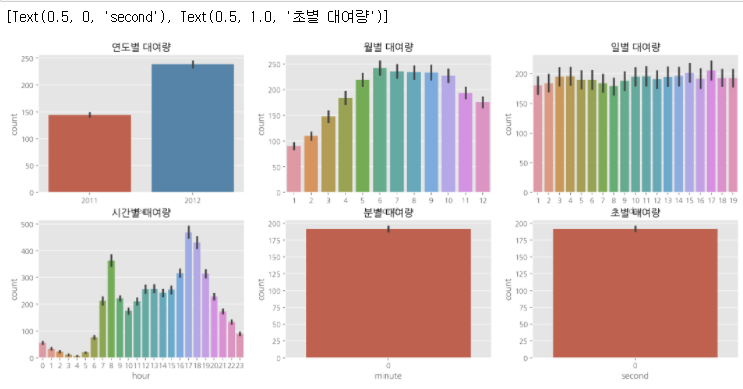
이처럼 분별, 초별 대여량은 모두 0으로 표시 되었기 때문에 모든 count가 0으로 나왔습니다.
따라서 이러한 그래프는 의미가 없으므로 지우고 다시 그렸습니다!
figure,((ax1, ax2) ,(ax3, ax4)) = plt.subplots(nrows = 2 , ncols = 2)
figure.set_size_inches(18,8)
sns.barplot(data=train, x='year', y='count', ax=ax1)
sns.barplot(data=train, x='month', y='count', ax=ax2)
sns.barplot(data=train, x='day', y='count', ax=ax3)
sns.barplot(data=train, x='hour', y='count', ax=ax4)
# sns.barplot(data=train, x='minute', y='count', ax=ax5)
# sns.barplot(data=train, x='second', y='count', ax=ax6)
ax1.set(ylabel= 'count', title='연도별 대여량')
ax2.set(xlabel= 'month', title='월별 대여량')
ax3.set(xlabel= 'day', title='일별 대여량')
ax4.set(xlabel= 'hour', title='시간별 대여량')
# ax5.set(xlabel= 'minute', title='분별 대여량')
# ax6.set(xlabel= 'second', title='초별 대여량')
- 위에서 막대그래프로 나타낸 그래프를 box그래프로 나타내 보겠습니다.
- subplots의 row와 col 선언을 통해 n*m개의 그래프 제작 , set_size_inches로 크기 조절
- axes를 통해 각 boxplot의 위치 지정
- 라벨링
fig, axes = plt.subplots(nrows = 2 , ncols=2 )
fig.set_size_inches(12,10)
sns.boxplot(data=train, y = 'count', orient= 'v' , ax=axes[0][0])
sns.boxplot(data=train, y = 'count', x= 'season' ,orient= 'v', ax=axes[0][1])
sns.boxplot(data=train, y = 'count',x= 'hour', orient= 'v' , ax=axes[1][0])
sns.boxplot(data=train, y = 'count', x= 'workingday',orient= 'v' , ax=axes[1][1])
axes[0][0].set(ylabel='Count', title ='대여량')
axes[0][1].set(xlabel='Season',ylabel= 'Count', title ='계절별 대여량')
axes[1][0].set(xlabel='Hour of The Day', ylabel= 'Count', title ='시간별 대여량')
axes[1][1].set(xlabel='Working Day', ylabel= 'Count', title ='근무일 여부에 따른 대여량')
평일을 나누어서 계산하기 위해서
일주일에서 평일의 요일 별로 계산하기 위해서
train['dayofweek']= train['datetime'].dt.dayofweek
train.shape
train['dayofweek'].value_counts()
[out]
5 1584
6 1579
3 1553
2 1551
0 1551
1 1539
4 1529
Name: dayofweek, dtype: int64이렇게 요일별 (0- 4 : 평일 , 5-6 : 주말) 자전거 대여량 수를 구분 하도록 했습니다.
요일별로 나눈 column을 가지고 새로운 표를 만들어 보겠습니다!
- 5개의 표 만들기 위해서 세팅
- 5개의 pointplot으로 시각화 , x축은 시간, y축은: hue column의 조건의 개수, hue : 조건
fig,(ax1,ax2,ax3,ax4,ax5) = plt.subplots(nrows = 5)
fig.set_size_inches(18,25)
sns.pointplot(data = train, x='hour', y='count', ax= ax1)
sns.pointplot(data = train, x='hour', y='count', hue = 'workingday',ax= ax2)
sns.pointplot(data = train, x='hour', y='count', hue = 'dayofweek',ax= ax3)
sns.pointplot(data = train, x='hour', y='count', hue = 'weather',ax= ax4)
sns.pointplot(data = train, x='hour', y='count', hue = 'season',ax= ax5)이렇게 5가지 표를 만들었습니다!

corrMatt = train[["temp", 'atemp','casual','registered', 'humidity','windspeed','count']]
corrMatt = corrMatt.corr()
print(corrMatt)
#상관관계 계산
mask = np.array(corrMatt)
mask[np.tril_indices_from(mask)] =False

상관관계
-> 상관관계는 1일수록 매우 관련이 있고, 0이면 관계가 없다. -1이면 반대관계이다.
히트맵
- 밝은 색일수록 양수인 상관관계가 크고, 어두운 색(검은색)일 수록 음수의 상관관계를 갖는다.
- 히트맵을 통해 시각적으로 한눈에 전체적인 상관관계를 파악할 수 있다.
온도, 습도, 풍속은 거의 연관관계가 없다.대여량과 가장 연관이 높은 요소는 registered이다. 이는 등록 된 대여자가 많지만, test 데이터에는 이 값이 없다.atemp와 temp는 0.98로 상관관계가 높지만 온도와 체감온도를 피처로 사용하기에는 적합하지 않을 수 있다.
fig, ax = plt.subplots()
fig.set_size_inches(20,10)
sns.heatmap(corrMatt, mask = mask , vmax=.8,square=True, annot = True)
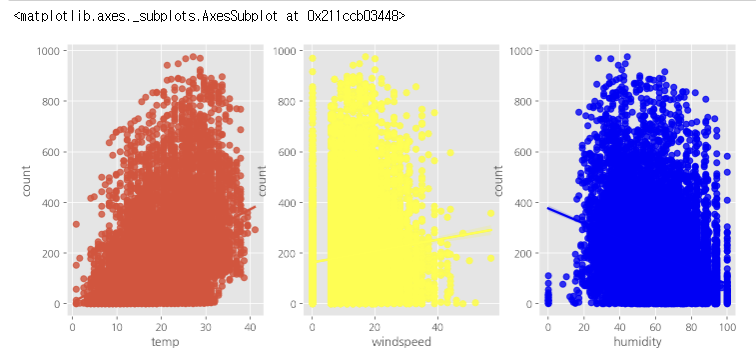
산점도
- 왼쪽부터 온도, 풍속, 습도의 산점도(regplot)이다.
- 풍속은 0에 몰려있고, 습도는 0과 100에도 있다.
fig,(ax1,ax2,ax3) = plt.subplots(ncols=3)
fig.set_size_inches(12,5)
sns.regplot(x = 'temp', y='count', data=train,ax = ax1)
sns.regplot(x = 'windspeed', y='count', data=train,ax = ax2, color ='yellow')
sns.regplot(x = 'humidity', y='count', data=train,ax = ax3, color= 'blue')
def concatenate_year_month(datetime):
return "{0}-{1}".format(datetime.year, datetime.month)
train['year_month'] = train['datetime'].apply(concatenate_year_month)
print(train.shape)
train[['datetime','year_month']].head()
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2)
fig.set_size_inches(18, 4)
sns.barplot(data=train, x='year', y="count", ax=ax1)
sns.barplot(data=train, x="month", y="count", ax=ax2)
fig, ax3 = plt.subplots(nrows=1, ncols=1)
fig.set_size_inches(18, 4)
sns.barplot(data=train, x="year_month", y="count", ax=ax3)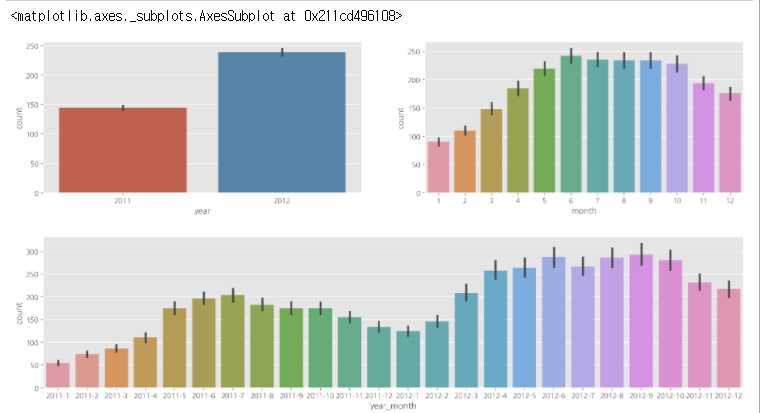
- 2011년보다 2012년의 대여량이 더 많은걸 알 수 있다.
- 2011년과 2012년의 월별 데이터를 비교하면 전체적으로 증가하는 추세이다.
- 따라서 공공 자전거 이용량이 증가하고 있다는걸 알 수 있다.
- 겨울보다는 여름에 대여량이 더 많다.
- 이상치(0에 몰려있거나 100으로 되어있는 값들)제거한다.
- train Without Outliers
trainWithoutOutliers = train[np.abs(train["count"] - train["count"].mean()) <= (3*train["count"].std())]
print(train.shape)
print(trainWithoutOutliers.shape)
[out]
(10886, 20)
(10739, 20)- count값의 데이터 분포도를 파악
figure, axes = plt.subplots(ncols=2, nrows=2)
figure.set_size_inches(12, 10)
sns.distplot(train["count"], ax=axes[0][0])
stats.probplot(train["count"], dist='norm', fit=True, plot=axes[0][1])
sns.distplot(np.log(trainWithoutOutliers["count"]), ax=axes[1][0])
stats.probplot(np.log1p(trainWithoutOutliers["count"]), dist='norm', fit=True, plot=axes[1][1])
count 변수가 오른쪽에 치우쳐져 있다.
대부분의 기계학습은 종속변수가 normal로, 정규분포를 갖는 것이 바람직하다.
대안으로 이상치 데이터를 제거하고 "count"변수에 로그르 씌워 변경해 봐도 정규분포를 따르지는 않지만,
이전 그래프보다는 좀 더 자세히 표현하고있다.
위의 분석은 [부스트코스] 캐글 실습으로 배우는
데이터 사이언스 - 자전거 수요량 예측을 위한 탐색적 데이터 분석을 토대로 작성했습니다!
'Make the Learning Curve > 부스트코스' 카테고리의 다른 글
| [부스트코스] 캐글 실습으로 배우는 데이터 사이언스 (0) | 2020.12.24 |
|---|---|
| [Kaggle] 캐글 첫 Commit (0) | 2020.12.23 |
| [부스트코스] 캐글 실습으로 배우는 데이터 사이언스 - 사이킷런 (0) | 2020.11.23 |
| [부스트코스] 캐글 실습으로 배우는 데이터 사이언스 (0) | 2020.11.03 |
| [부스트코스] 네이버 부스트코스 시작 (0) | 2020.11.03 |




댓글